基盤モデルの現在と未来~マルチモーダル基盤モデルの動向からLLMの先を占う~

ChatGPTのリリースにより、自然言語基盤モデル(大規模言語モデル、LLM)は新たなステージへ突入し、さまざまなところで利活用が始まっています。一方で、基盤モデルには「様々なモダリティの全てのデータからの情報を一元化し、一つのモデルを下流のさまざまなタスクに適応させられるようになる」というゴールイメージがあります。
マルチモーダル、シングルモデル、マルチタスクなモデルの研究はどこまで進んでいるのでしょうか? 本記事では研究事例の紹介なども含め、その今後の動向を探ります。
※:本記事は、2023年11~12月開催の「MET2023」の講演を基に制作したものです。
【講演者】

目次
基盤モデルとは
最初に、基盤モデルの概要から解説します。基盤モデルは多様な種類のデータを受け取り、それに応じた適切な回答を生成するAIモデルのことで、英語では「ファウンデーションモデル」と呼ばれます。将来的にはテキスト・音声・画像・動画はもちろん、人間の五感では捉えられないセンサーデータなど、より多種多様なデータタイプの対応を目指していることも特徴のひとつです。そして、入力される各データに応じた、適切な形式でのアウトプット生成能力の獲得が期待されています。
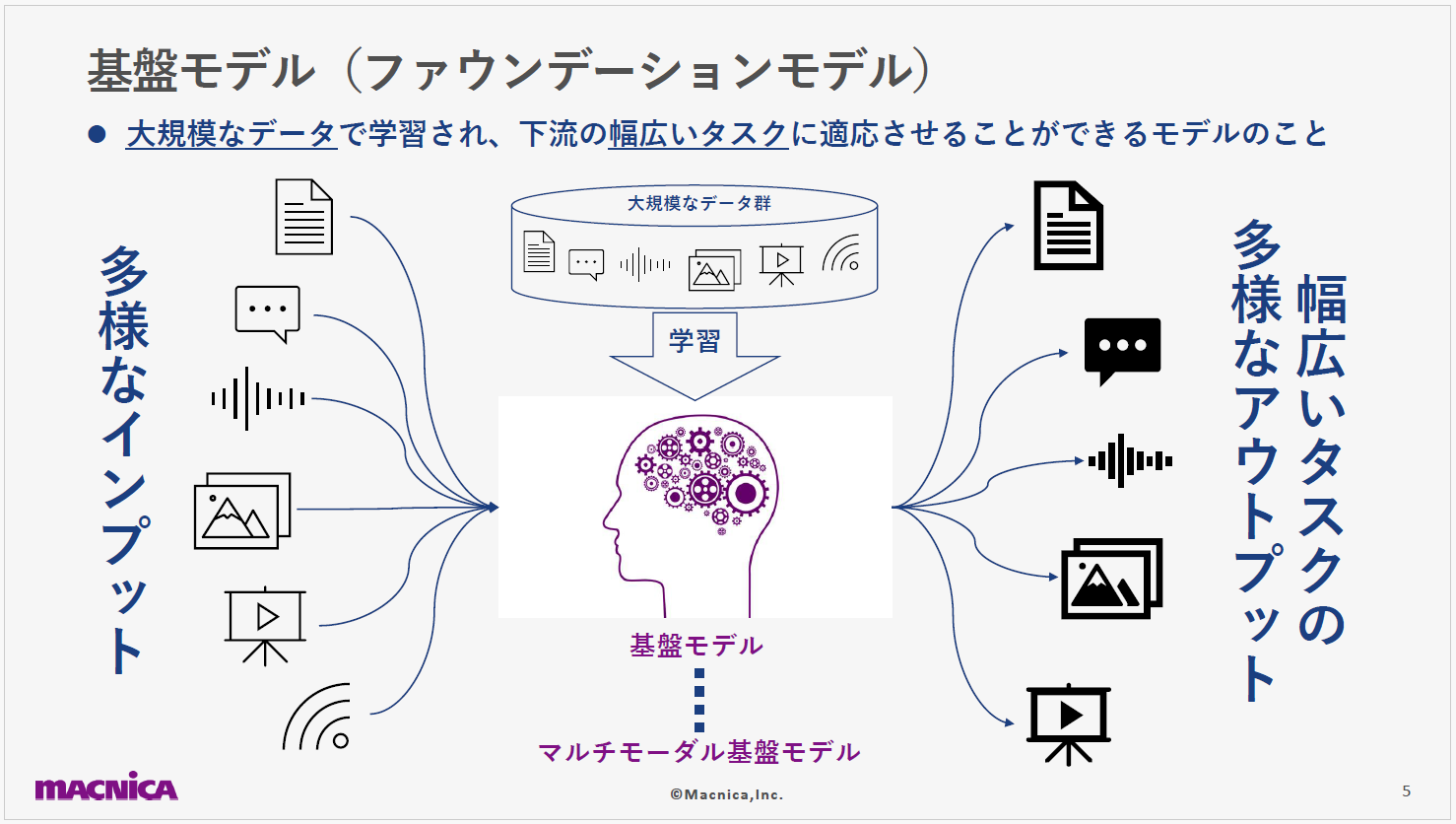
また、多種多様なデータタイプは「マルチモーダルデータ」、それらを扱える基盤モデルは特に「マルチモーダル基盤モデル」と呼ばれます。膨大なデータ量での学習がこのモデルの基盤となっており、その結果、モデルのパラメーター数も非常に多くなっています。しかし、今後のモデルの効率化が進めば、少ないパラメーターでより良い性能が出せるようになるかもしれません。
現在は、下記の2パターンが多くの場で実際に利用されています。
1つ目は テキストを受け取り、テキストで応答するモデルです。このモデルは、応用例がチャットボットなどに限られます。OpenAI社のChatGPTも、最初はテキストからテキストへの変換をするLLMとしてスタートしました。
2つ目は、入力されたテキストから関連画像を生成するモデルです。 たとえば「夕日の風景」と入力すると、それに該当する風景画像が出力されます。2023年9月には、ChatGPTにも、この機能が追加されました。
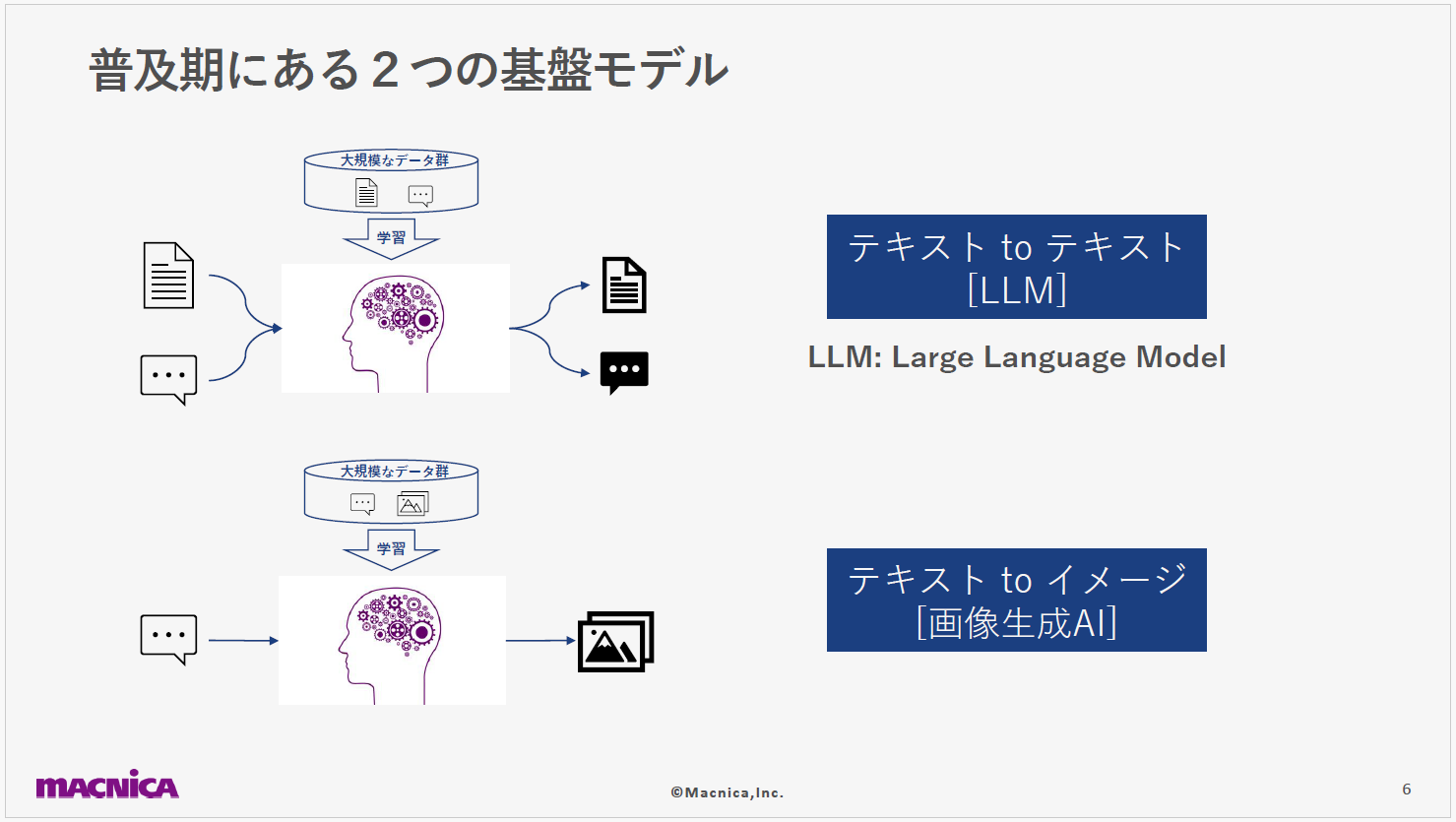
これら2つのモデルは、こんにちのAI技術の発展において中心的な役割を果たしています。LLMは情報の検索や文章生成の分野、画像生成AIはビジュアルコンテンツの制作や編集の分野で、それぞれ画期的な変革をもたらしています。
2022年から2023年にかけての1年は、LLMにとって非常に多くの変動がありました。2022年11月にOpenAI社がChatGPT3.5を公開し、AIに馴染みのなかった多くの人々の目にも触れることになり、その存在が急激に認識されるようになりました。さらに、2023年3月にはGPT4が公開され、その高い能力に「テクノロジーのシンギュラリティが近いのではないか」という意見も出てきました。
一方、現在のLLMの基礎となっているトランスフォーマーの原理を生み出したGoogle社は、Birdという独自のLLMをリリースしました。オープンソースモデルも進化を続けており、OpenAI社の技術とどれほど競合しているか、またはそれを超えているかということが指標として示され、注目されています。
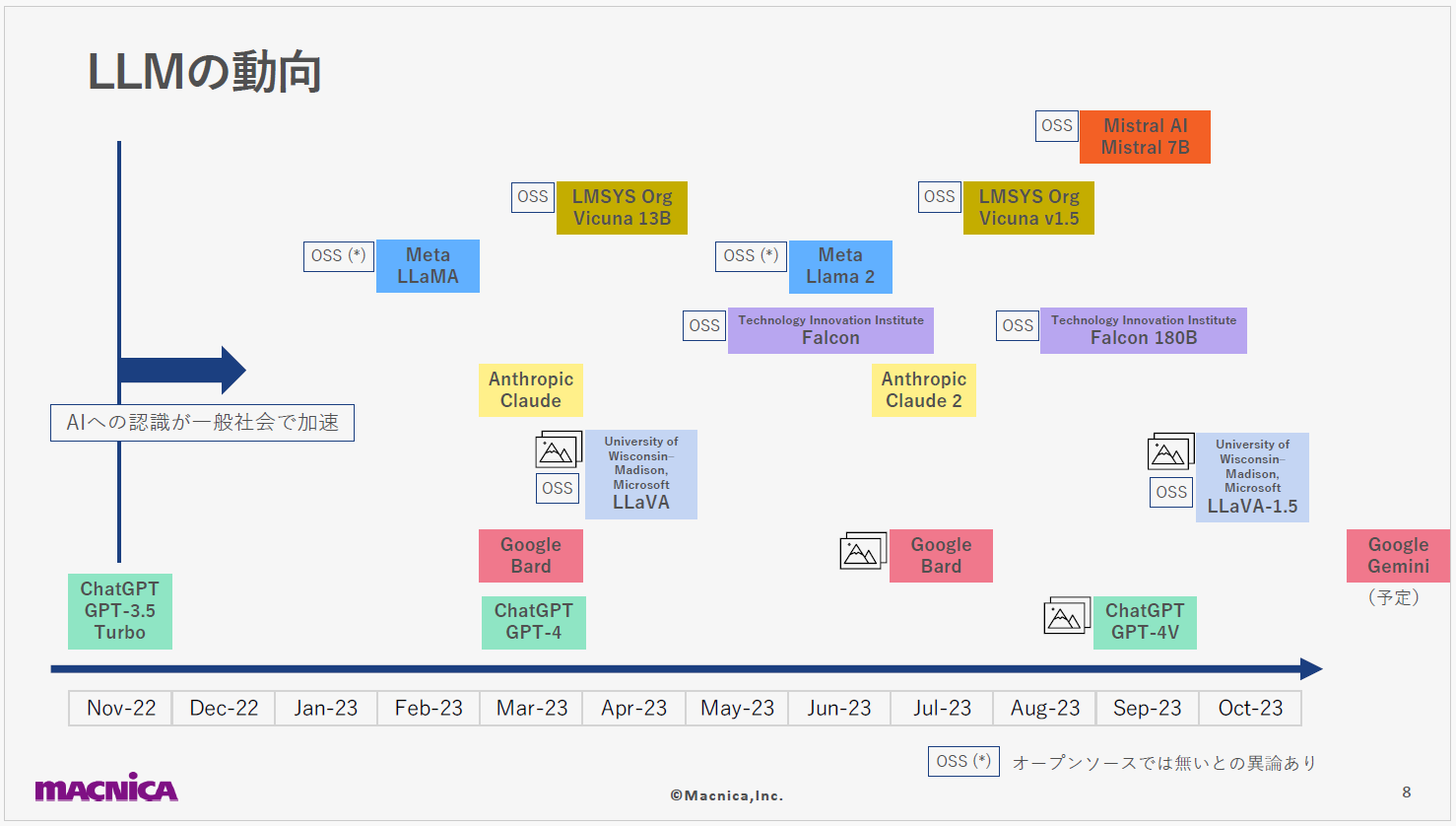
オープンソースモデルには、機密データを使用して独自のLLMモデルを構築できるというメリットもあります。最近では、Bird・LLaVA・GPT4など、テキストに限らず画像も組み合わせた入力が可能なモデルが登場しています。
また、従来の画像生成AIはアウトプットが画像でしたが、前述した3種は 画像を入力することもできることから、テキストと画像を組み合わせたさまざまなタスクへの応用が期待できます。これは、マルチモーダル化の流れを象徴しています。GoogleからもGeminiという新モデルのリリースが予告されており、業界の動向から目が離せません。
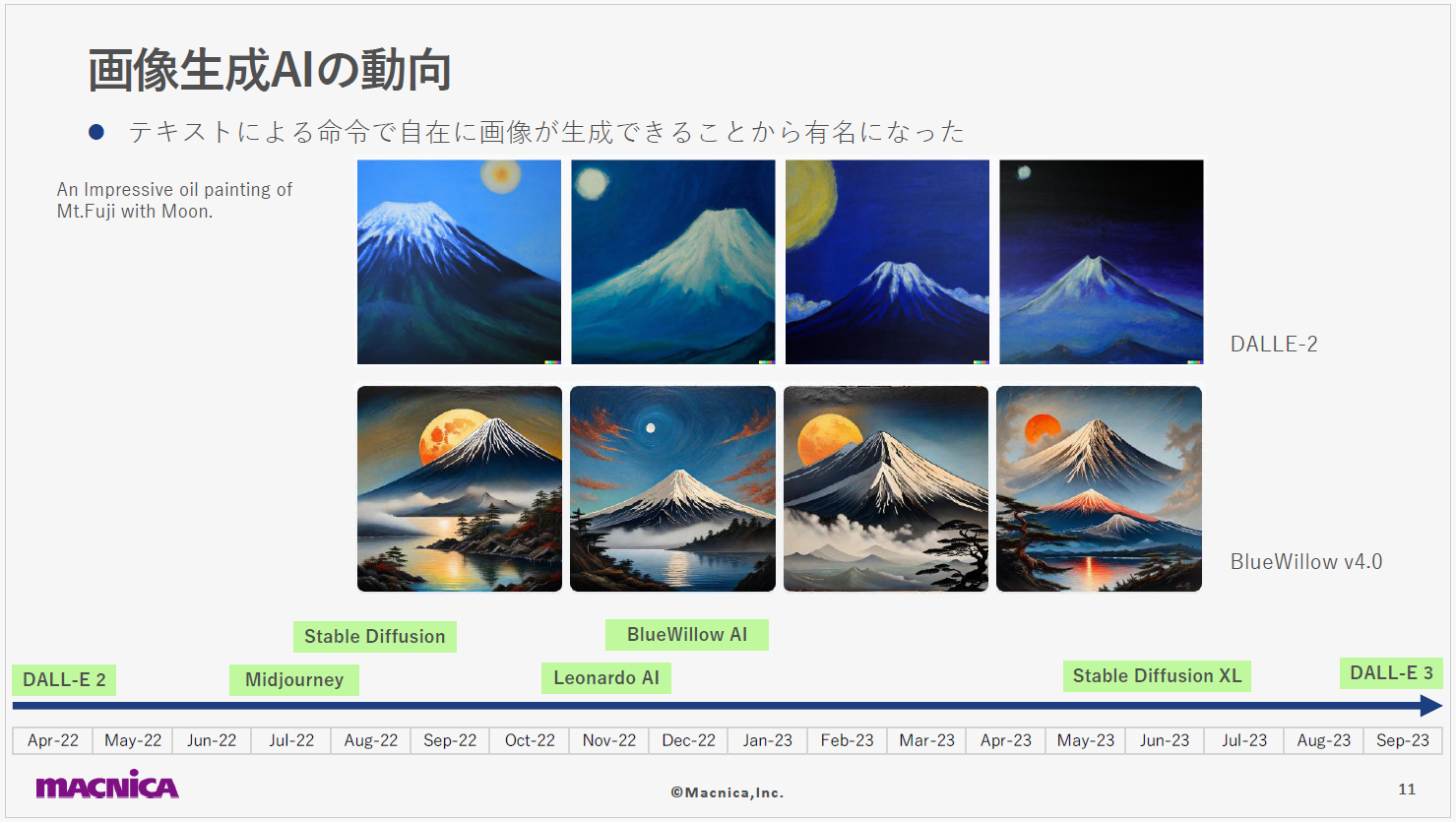
画像を生成する技術には、過去にも色々なものがありました。たとえば、2018年にはGAN という技術で生成した絵画がニューヨークの43万2千ドル(当時のレート換算で約4,700万円)で落札されており、当時から一定の注目を集めていました。それから時が流れ、誰もが気軽に画像生成AIを利用できるようになってきました。2022年のDALL-E 2の発表後にさまざまな画像生成AIがリリースされ、以降も活発な動きのある状況が続いています。さらに、2023年9月にはDALL-E 3もリリースされました。これらはいずれも、テキストの指示によって画像を生成します。
こちらの画像は、DALL-E 2とBlueWillow v4.0にそれぞれ「An Impressive oil painting of Mt.Fuji with Moon.」と打ち込んで出力したものです。前者は絵筆のタッチを表現した油絵風になっているのに対して、後者は細部に渡る描写がより精緻になっているように感じます。
さらに、下記のスライドはDALL-E 3による出力です。先ほどの画像と比較すると、こちらは色の深みとバリエーションが際立っています。クラシックの油絵のスタイルとモダンなデジタルアートの中間のようなスタイルで、水面の揺らぎや雲のテクスチャ―、植物の描写など、細部に至るまで非常に精緻な表現をしています。

DALL-E 3はユーザーが入力したテキストから、具体的な描写をするための4つのテキストを生成し、それらを基に画像を生成しています。DALL-E 2やBlueWillow v4.0がリアルな表現が強かったのに対し、中間のような位置づけであるとも言えるかもしれません。総合的に見て、DALL-E 3はテキストの詳細に非常に敏感で、リアリスティックかつアーティスティックな画像生成が可能なようです。こうした進化から、AIの画像生成能力はどんどん向上していることが確認できます。
OpenAI社が出した論文によれば、学習に使用するイメージと、そのイメージを説明するテキストをより詳細にした良質なデータを用意し、それらを学習させることで、このような画像生成が可能になったようです。ただ、著しい進歩が見られる一方で、社会への実装に関する課題や懸念が増加しており、倫理や規制に関する議論も活発になってきています。その一例となるのが、下記です。一番左がオリジナルの写真で、それ以外はDALL-E 2によって生成された類似画像です。このように、画像生成AIがオリジナルの作品に近い画像を容易に生成できることから、著作権に関する議論が急速に高まっているというわけです。
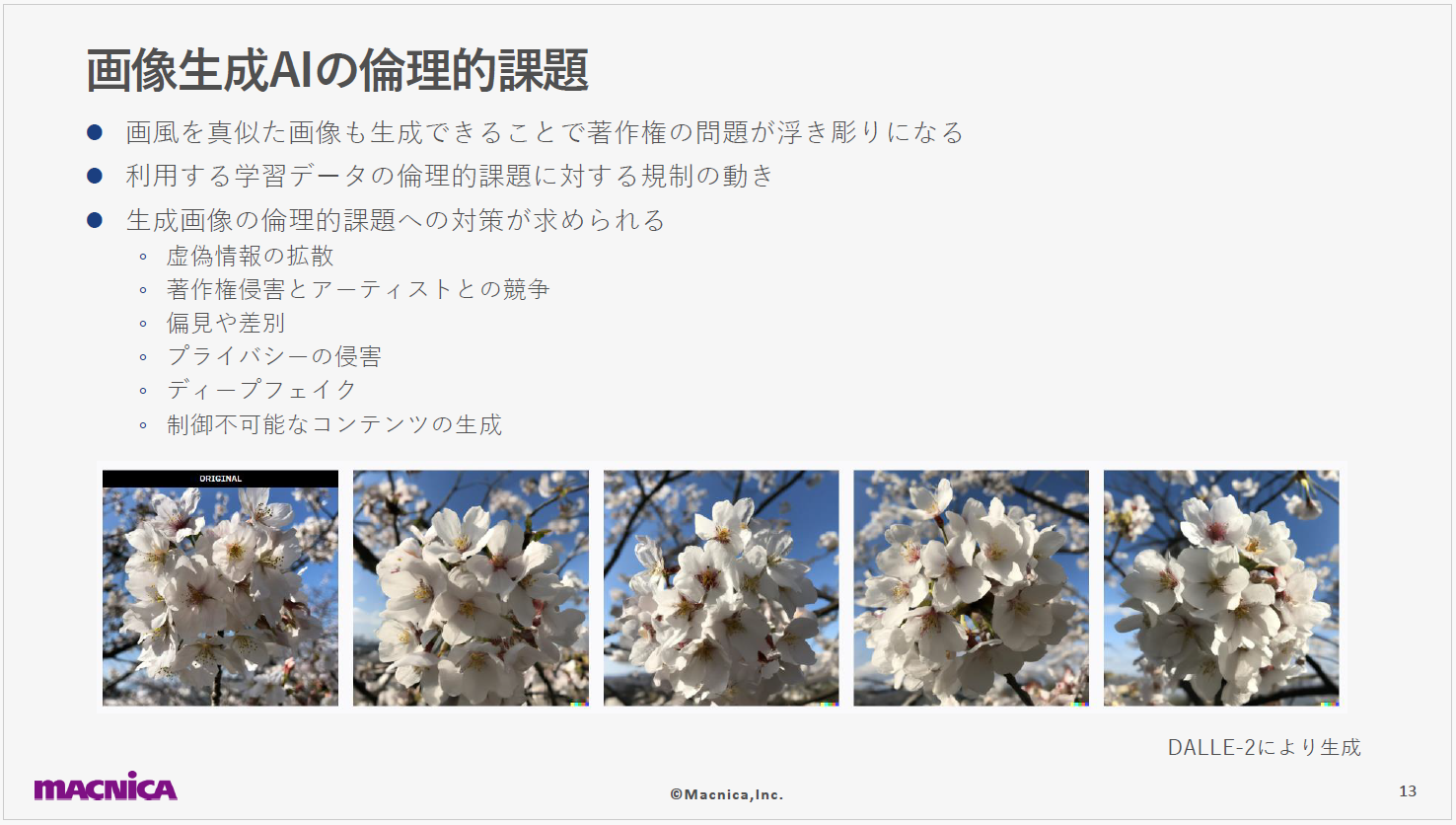
加えて、虚偽情報の拡散・社会的な偏見や差別・プライバシー侵害・ディープフェイクや制御不能なコンテンツの生成など、多くの社会的課題がこの技術によって引き起こされ得ると議論されています。なお、DALL-E 3には類似画像の生成機能はないようです。
従来は入力されたテキストに対して、テキストや画像を出力するLLMや画像生成AIが基盤モデルにおける主流でした。ところが、最近では入出力の両方でさまざまな形式のデータを扱えるマルチモーダル基盤モデルの研究が進められており、これをLMM(Large Multi modal foundation Model)と呼ぶ研究者も増えてきました。
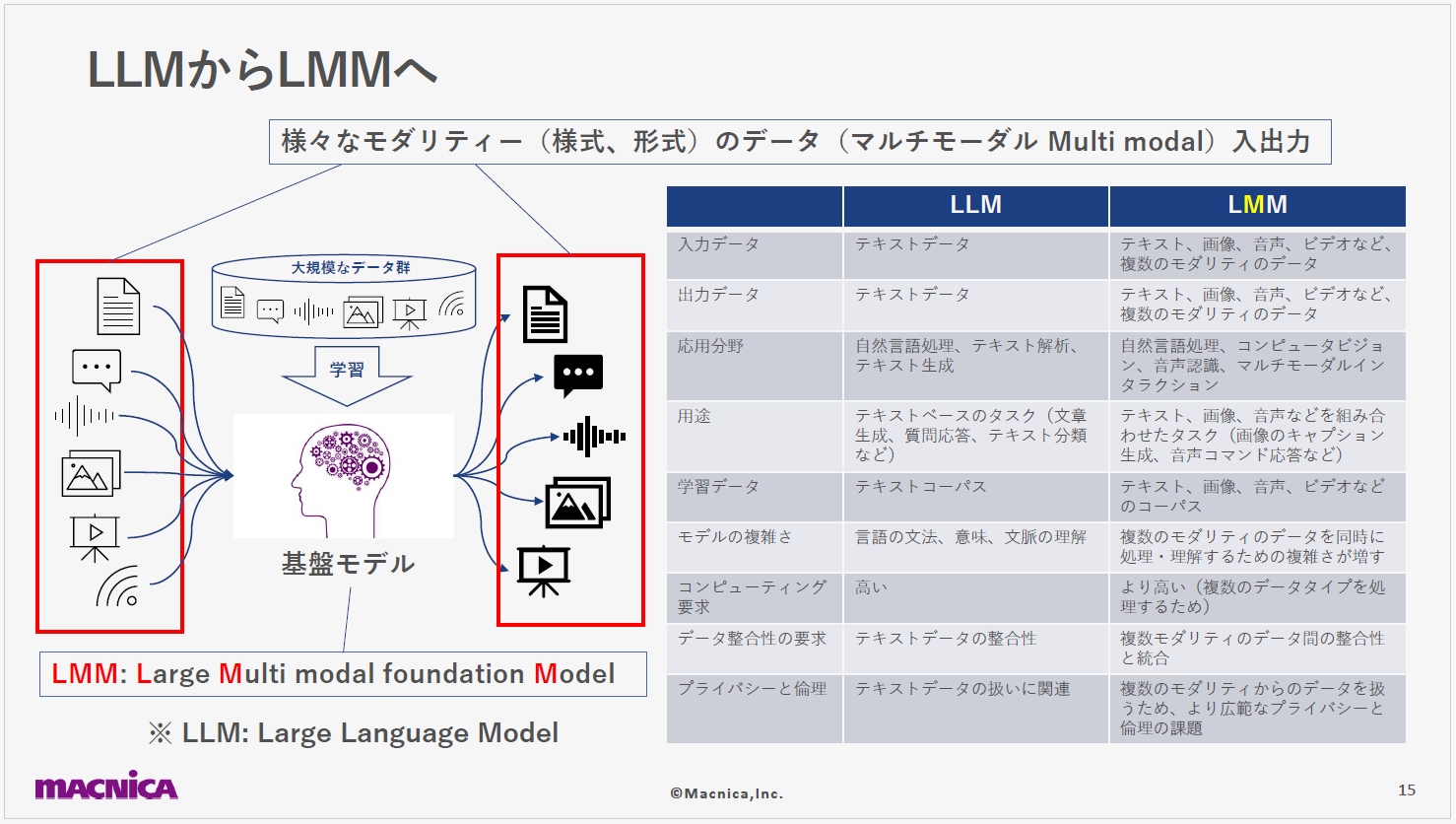
マルチモーダルデータを取り入れられれば、「音声から画像へ」「テキストから音声へ」「センサーデータからテキストへ」などの変換が可能になることが期待されます。たとえば医療では画像・テキスト・音声データを組み合わせて正確な診断を支援したり、製造業ではセンサーデータ・画像・テキストログを分析して機械の故障を予測したり、といったことが実現するかもしれません。

技術の進化にともない、モデルの複雑さや必要な計算リソースは増大すると思われますが、その利用範囲も飛躍的に広がり、多岐にわたる分野での活用が期待されます。これが実現すれば、私たちの生活や仕事の質が向上することは間違いないと思います。一方で、 新たな技術がもたらす社会的な課題にも私たちは目を向ける必要があるでしょう。
マルチモーダル基盤モデルの現状
2023年3月のGPT4リリースから半年後となる9月、OpenAIはGPT4Vを公開しました。このバージョンでは画像を入力し、それに対する質問を行えます。以前、日本の交通標識をどれくらい認識できるか試してみたところ、9つのうち7つは正解しました。間違った答えもありましたが、画像の意味と特徴を捉えた回答が現実のものになってきていると感じます。
OpenAIは、GPT4Vのリリース後にビジョンシステムカードという論文を公開しました。この論文では、2023年3月のGPT4のリリース以降の画像解釈における安全性の向上について触れられています。また、有害性・偏見・サイバーセキュリティ・プライバシー・脱獄などのリスクに対して、モデルが回答を拒否するように訓練されることも明記されています。初期のGPT4ではバイアスの影響を受けた回答が示されることがありましたが、GPT4Vではそのような回答を拒否する動作となるようです。
オープンソースのLMMは、以前のLLM同様、オープンソースのプロジェクトとしても研究が盛んに進められています。下記の表はその一部を示しており、マルチモーダルやクロスモーダルなモデルが研究室での実装段階にあることが確認できます。クロスモーダルとは、テキスト入力から音声回答を生成したり、 音声とテキストの入力から画像を出力するような、異なるモダリティー間の変換を実現する技術を指します。

なかでも特に注目してご紹介したいのは、ImageBindとNExT-GPTの2つです。まずImageBindは、マルチモーダル基盤モデルそのものではなく、異なるモダリティー間の変化に適用可能な技術として注目されています。
かつては、異なるモダリティー同士での対象学習により、モダリティーの変換が可能であることが知られていました。ところが本研究では、画像とのペアのみを学習すれば、 直接学習していないモダリティーも共通のエンベディング空間にマッピングできることが明らかになったのです。異なるモダリティー間の関連性も確立できるようになったことは、非常に革新的な結果だと言えます。
このスライドは、テキスト・オーディオ・画像といった、異なる3つのモダリティがどのようにエンベディング空間内で表現されているかを示しています。
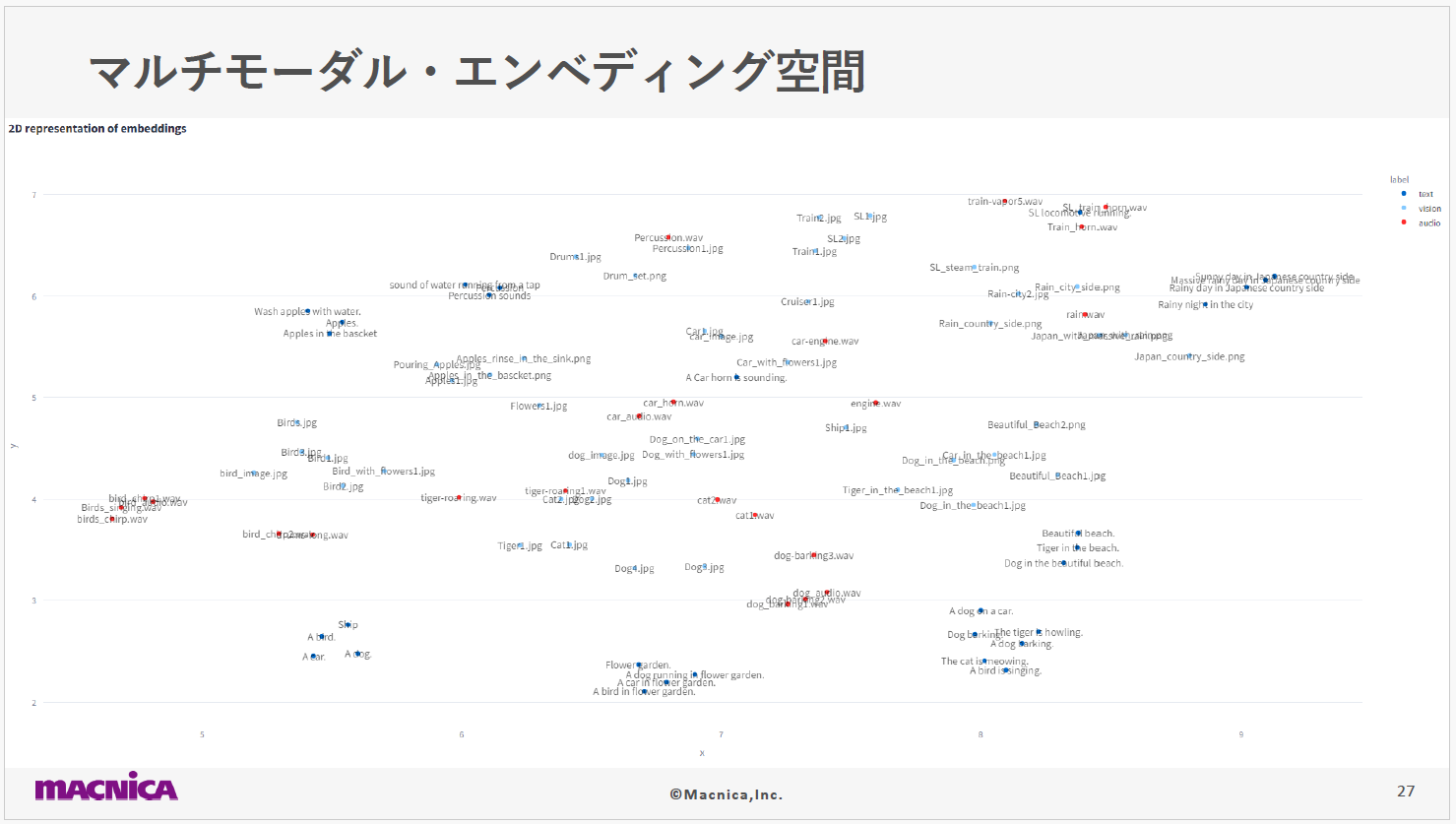
ImageBind の事前学習モデルを用いて、これらのモダリティごとのデータは1,024次元のエンベディング空間にマッピングされます。今回は視覚的に分かりやすく表示するために、この1,024次元を二次元に次元圧縮し、図のようにプロットしました。テキストが青・イメージが水色・オーディオが赤で表現されており、これによって各モダリティのデータがどのように分布しているかを把握できます。図を詳しく見てみると、関連性の高い要素はエンベリング空間内で近くに位置していることが確認できます。
次に、NExT-GPTを紹介します。これはマルチモーダル間での自由な入出力を実現するクロスモーダルモデルで、シンガポールのNational University of Singaporeで開発されました。
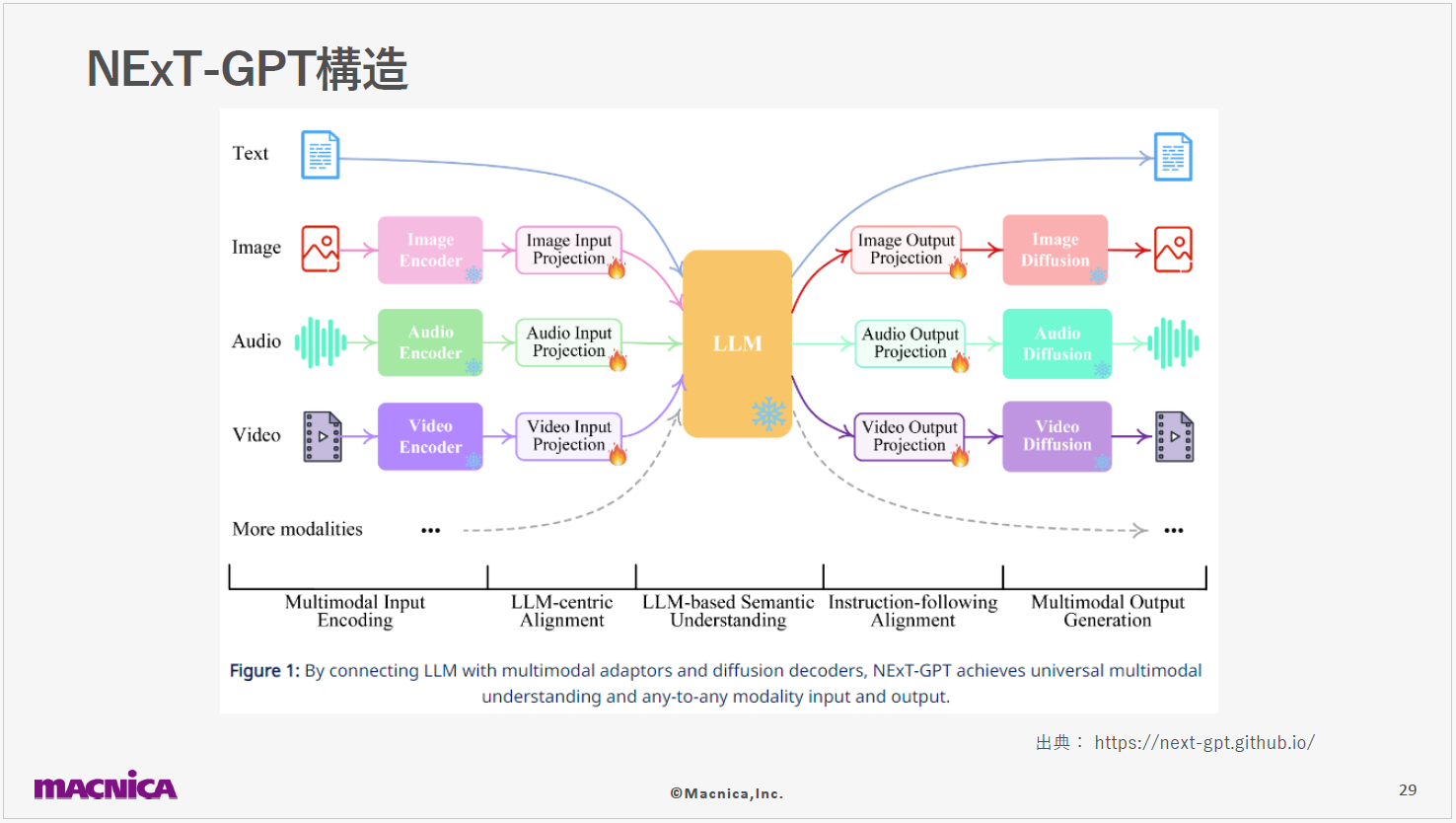
まずエンコーディングステージにはImageBindの技術が活用されており、画像・オーディオ・ビデオを効率的にエンコードします。
次に、インプットプロジェクションステージでImageBindからのエンコード情報をLLMが理解しやすい形式に変換します。VicunaをLLMとして採用していることも特徴で、これが各モダリティーからの入力を受け取り、それを解釈して意味理解や推論を行います。具体的には、テキストレスポンスの生成や出力モダリティーの選択指示としてのシグナルトークンを出力します。
続いてアウトプットプロジェクションステージでVicunaからの出力を受け取り、それを対応するモダリティーのデータに変換します。 そして最後に、Vicunaからの指示に基づいて特定のモダリティーのコンテンツが生成される仕組みです。
画像生成にはStable Diffusion、ビデオ生成にはZeroscope、オーディオ生成にはAudioLDMなどの技術が利用されています。 このように、NExTGPTのアーキテクチャーは多様な入力情報を受け入れ、それに応じて最適な出力を生成する高い柔軟性をもち、効率的にマルチモーダルデータの統合や変換を可能とします。
未来の展望
最後に、基盤モデルの背景も含めた今後の方向性や未来の可能性についてお話します。大規模な自然言語処理モデルであるLLMは、すでに社会実装のフェーズに進んでおり、その結果、多様なアプリケーションやユースケースが次々と誕生しています。LLM進展を基に、テキストに加えて イメージの入力がじ現実的になり、より幅広い社会実装が可能な状態が近づいています。

また、NExTGPTをはじめとするマルチモーダル入出力の技術も確立しつつあり、音声や画像だけではなく、人間には感知できないセンサー情報も取り込むことができ、 外制御やロボティックスにおいても多くの応用が期待されます。
従来のLLMは大規模化が主流でしたが、より小型ながら高性能なモデルも誕生しており、 このアプローチがマルチモーダル基盤モデルにも良い影響を与えると考えられます。LLMやLMMには、オープンソースを利用する方法とSaaSを利用する方法がありますが、今後は両方が進展し、ユーザーは利用用途や条件に応じた使い分けができるようになるでしょう。しかし、こうした技術に対する社会的な懸念も存在します。それらに対処するためには、社会的な規制と技術のさらなる発展が必要です。
数年から数十年後、マルチモーダル基盤モデルが完全に成熟した場合、何が可能になるのでしょうか。それをまとめたのが、こちらの表です。

1つ目は、リアルタイムインテリジェンスです。 瞬間的な判断が求められる状況で、AIは人間を凌駕する高速かつ正確な分析を提供できるでしょう。2つ目は、協働、コラボレーションです。AIは、医療・学術・芸術などの領域で、専門的なアドバイザーとして、 人間とともに新たな価値を生み出すことが可能となるでしょう。3つ目は、状況適応性です。不確実な環境や予期せぬ事態に対して、AIは事実的に適応し、最適な解決策を生成できるようになるでしょう。4つ目は、人間性の理解です。AIが人間の心に密接に接触すれば、より繊細な会話やサポートが可能になるでしょう。
AIの未来に対する課題と挑戦についても深掘りします。
1つ目のポイントは、AIと倫理です。AIがもつ倫理的な課題は多岐にわたりますが、主なものとしては、プライバシーの侵害・地域ごとに異なる社会的・文化的価値観・AIが生成する偏見やバイアスなどが挙げられます。これらの課題に対処するためには、社会的・文化的価値観を一定の基準で標準化し、その過程を透明にして監視する仕組みが欠かせません。
2つ目は、適切なAI依存度です。AIとの関係性を健全に保つためには、依存レベルを適切に管理し、 人間とAIが調和して共存する手段を見つける必要があります。人間がAIに対して過度に依存する状態は、望ましい未来像ではないと思います。
3つ目は、労働市場の変革です。AIの進展により、職業の性質が変わるだけではなく、新たな職種も生まれています。これに適応するための教育と研修も重要です。
4つ目は、技術の制約と影響です。計算機の物理的な限界や、大規模モデルが環境に与える影響など、技術的及び社会的な側面でも課題が存在します。特に、マルチモーダル基盤モデルは大量のデータと計算リソースを必要とするため、CPUやGPUのリソース確保、 それにともなうCO2排出量も注視すべき課題です。
このように、多くの課題と向き合う必要はありますが、マルチモーダル基盤モデルには高い潜在能力があり、生活を豊かにする可能性が確かに存在します。